1. JVM G1 Region 分区详解
1.1. G1垃圾回收器的简单介绍(垃圾优先回收器)
1.1.1. 垃圾回收优先
G1垃圾回收器,也叫垃圾回收优先回收器(Garbage-First,G1),它会优先回收垃圾,不会等到空间全部占满,再进行回收。
1.1.2. 停顿预测模型
停顿预测模型,预测一次回收可以回收的分区数量,以满足对停顿时间的要求。
1.1.3. 化整为零的分区机制
ParNew + CMS 回收器的分区是:新生代,老年代,s区。
G1是把一整个大块儿的内存,分成n个相同大小的分区(Region)。这种灵活可变的 Region 机制设计,是G1能够做到控制停顿时间的核心。
1.2. 传统的分代模型和G1的内存模型对比
1.2.1. G1 内存分区类型
HeapRegion 是G1垃圾回收器内存管理的基本单位,也是最小单位。分区类别如下:
- 新生代分区:Young Heap Region (YHR)
- 自由分区:Free Heap Region (FHR)
- 老年代分区:Old Heap Region (OHR)
- 大对象分区:Humongous Heap Region (HHR)
1.2.2. ParNew+CMS 与 G1 的内存模型对比
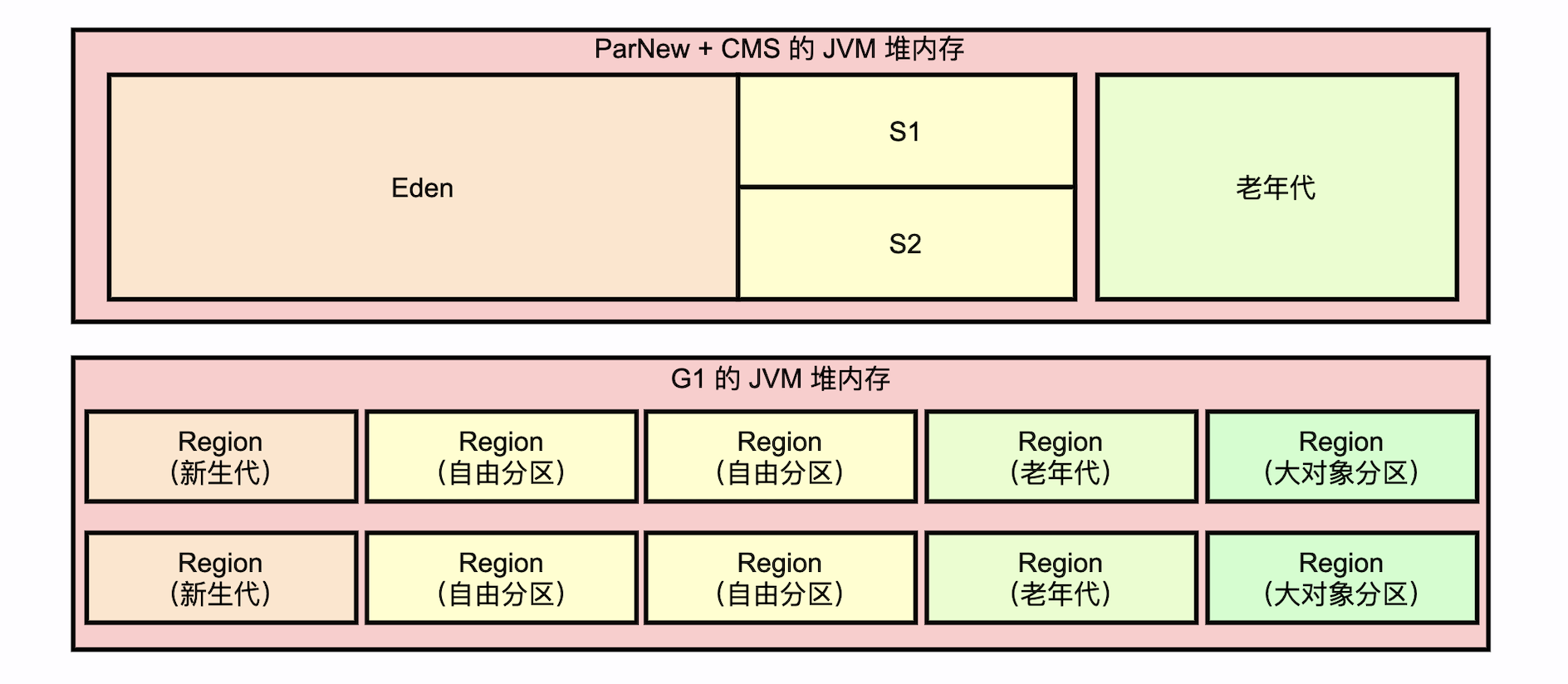
ParNew+CMS优势:它不用做很多复杂分区管理的相关的处理。并且小内存时,垃圾回收不会造成很大的停顿。
ParNew+CMS劣势:堆内存很大时,例如64GB的堆内存,eden区可能 20~30GB,回收一次eden区要2~3s,会导致系统停顿时间过长。
内存分代模型中,传统的分代模型是按照块状来做内存分配,这种分配管理的方式,在大内存垃圾回收时会有一些不足。会出现一次GC时间过长,导致stop the world时间较长,严重的情况下,会对用户体验造成比较大的影响。
针对大内存场景,诞生了G1垃圾回收器,G1管理内存时,直接将内存块,分割成n个小内存块,根据需求,动态的分配给新生代,老年代,大对象来使用,同时 G1 会根据垃圾回收的情况动态改变 新生代、老年代、大对象分区 的大小(即Region个数)。
例如,有对象需要分配时,可能会对新生代进行扩展(动态变化:新增几个Region,或减少几个Region)。当垃圾回收时间比较长,说明GC压力太大,系统会根据情况适当少分配一些分区。
G1 会保证回收和程序运行的平衡。
1.3. G1 的 HeapRegion(HR)
1.3.1. G1如何设置HeapRegion(HR)的大小?
手动式 —— 通过参数设置 G1HeapRegionSize,默认为0
Region的大小限制,范围,1-32MB,同时需要满足 1、2、4、8、16、32。
启发式推断 —— G1本身通过算法自动计算 G1根据内存(堆内存大小、分区的个数)的情况自动计算出Region大小
注意:Region的大小,只能在1-32MB之间,不能小于1MB,也不能大于32MB,并且要满足是2的n次方。即,1,2,4,8,16,32这几个值。如果指定的值不是这个范围内的值,G1会根据一定的算法规则自动调整。
1.3.2. HR的大小会对垃圾回收造成什么影响?为什么要设置成1、2、4、8、16、32?
如果Region过小,例如,256KB?这样会造成对象分配的性能问题。
系统运行后,创建对象,大部分可能是几十到几百KB。
第一,找到一个可以使用的Region难度增加。
分配一个对象需要找Region的次数会变多。 Region 太小,很容易导致剩余的空间大小不够放下一个新的对象,需要不断的找满足条件的 Region。
第二,跨分区存储的概率增加。
Region分区越小,说明同样的内存大小,可以存储的对象越少,很可能出现,大量稍微大一点的对象,就超过了一个Region的大小,那么只能跨分区存储一个对象,即要用多个Region去存储一个对象,这时,分配一个对象的开销会比较大。
如果Region过大,例如,64MB,128MB,256MB?会造成GC性能问题。
第一:Region回收价值的判定很麻烦。
Region设定的内存越大,判断内部对象存活状态的时间会变长,做回收性价比的时间也会变长。
第二:回收的判定过程会更加复杂。
垃圾回收的时候,需要判断哪些对象需要回收,Region越大,对象越多,情况可能也会更复杂。
为了平衡分配效率和回收的效率。在保证两者的性能的同时,设置一个合理的Region分区大小。
为什么要设置成 1 2 4 8 16 32这几个值的范围?2的n次方
第一,如果不是2的n次方,会造成内存碎片,内存浪费的问题
一般内存的分配都是几个G,比如2048 MB、4096MB、8G、32G,如果一个Region = 3MB、15MB、23MB,分区数量不能整除,有可能分区数量不是整数,可能导致内存碎片,有一部分没有利用上。也增加实现的复杂度。
第二,如果不是2的n次方,计算机底层无法利用2进制计算速度快的特性
计算机底层是二进制的,如果使用非2的n次幂的数,在Region数量计算,自动扩展Region数量的时候,有可能无法利用计算机底层2进制计算的速度快的特性。(位运算速度非常快。)
2 * 2 , 1 << 2来做计算。
1.3.3. Region的大小到底是如何计算的?
堆分区的个数
默认2048个,这个数字会根据具体的内存大小自动计算。
计算 Region size 的时候,会直接用这个默认的2048这个值。
堆内存的大小
默认最大96MB,最小为0MB
设置InitialHeapSize相当于设置Xms,设置MaxHeapSize相当于设置Xmx
计算公式
Region_size = max(( InitialHeapSize + MaxHeapSize )/ 2 / 2048 , 1MB)[1,32]最小值
例子
第一种,只指定Region大小:
假如Region大小设置为2MB,则G1的总内存大小为,2048 * 2MB = 4GB 分区个数2048
第二种,指定堆内存大小,且最大值等于最小值:
假如设置堆内存大小: Xms,Xmx,并且 Xms = Xmx=32GB,则 RegionSize = max((32GB+32GB)/2 / 2048) , 1MB) = 16MB
第三种,指定堆内存大小,且最大值不等于最小值:
假如设置堆内存大小Xms,Xmx,并且 Xms = 32GB,Xmx=128GB,则 RegionSize = max((32GB+128GB)/2/2048 , 1MB) = 32MB。并且由于G1垃圾回收器会自动计算分区个数,在这个例子中,分区的个数范围在 32GB/32MB=1024 ~ 128GB/32MB=4096之间。
假如设置堆内存大小Xms,Xmx,并且 Xms = 64GB,Xmx=256GB,则 RegionSize = min(max((32GB+128GB)/2/2048 , 1MB) , 32MB) = 32MB。并且由于G1垃圾回收器会自动计算分区个数,在这个例子中,分区的个数范围在 64GB/32MB=2048 ~ 256GB/32MB=8192之间。
1.3.4. RegionSize如果不符合规则,G1是怎么处理的?
RegionSize如果设置成3MB,或者1.5MB,64MB,不符合G1的限制条件,会怎么样?
或者,堆内存是3G,计算出来的RegionSize是一个非2的n次幂,G1会做什么处理?
答案是会做动态调整Region Size,向2的n次幂对齐。
计算RegionSize得到的结果不是2^n时,会向2^n对齐,具体的对齐规则是,从计算得到的数字中,找到数字里包含的最大的2^n幂。
举例:如果计算出来的结果是1.5MB,那么RegionSize对齐后的结果就是1MB;如果是3MB,那么RegionSize对齐后的结果就是2MB;如果计算出来是9MB,那么RegionSize对齐后的结果就是8MB。自己设置的RegionSize也一样,参考对齐规则。
1.3.5. Region数量
在计算RegionSize的时候,会使用默认的2048分区数来计算RegionSize,RegionSize会被动态调整成一个合理的值。如果RegionSize没有调整与或者计算出来的一致,并且堆内存不会动态扩展的时候,堆分区的数量才是2048这个值!
否则,分区数量 为 堆内存大小 除以 上面计算出来的RegionSize。是动态计算出来的,不能设置。
注意:G1不能手动指定分区个数!!!