1. JVM G1 停顿预测模型
1.1. 如何满足用户设定的停顿时间?
1.1.1. 首先要预测,在停顿时间范围(200ms)内,能回收多少垃圾? --- G1的停顿预测模型
对接下来要进行的回收进行一个预测,比如,预测能在200ms内回收2GB的垃圾,那就选择2GB内存对应的的region来进行回收。
1.1.2. 预测的基石是什么?肯定不能凭空瞎预测吧?
预测的基石,一定是要有GC相关的历史数据。因为之后GC运行的情况才有参考,能反应出来GC的能力的强弱。例如,历史10次GC,每次GC时长,回收垃圾情况等的。
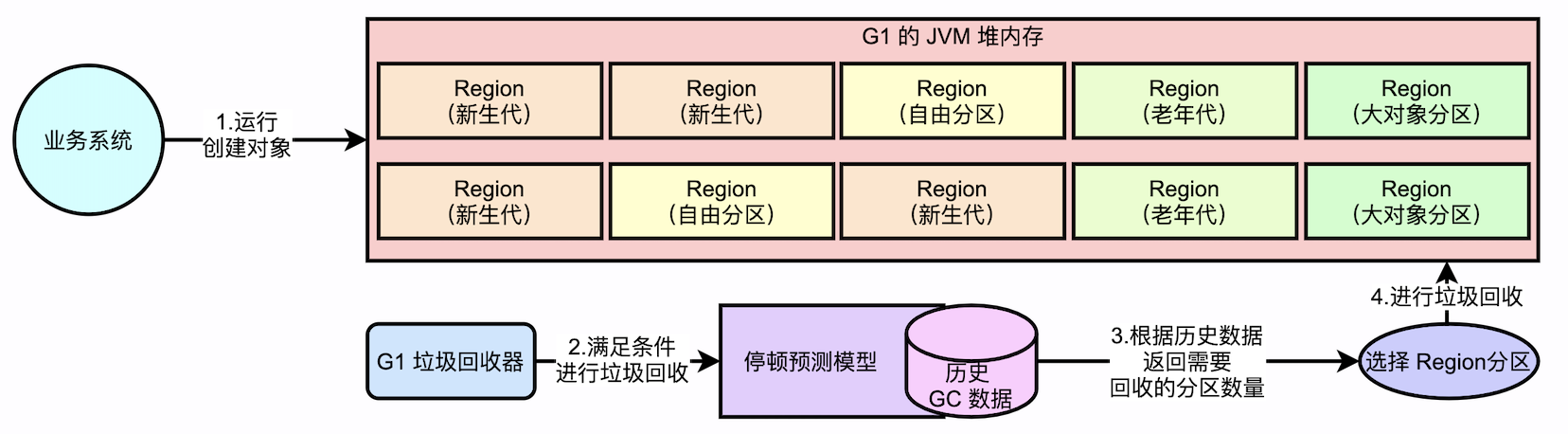
1.1.3. 应该怎么预测?拿到历史数据该怎么用?
一个基本的逻辑就是,如果目标停顿时间短,就少收点分区,目标停顿时间长,就多收点分区。
要知道回收的能力是多少(可以参考历次回收相关的历史数据,来帮助分析到底回收的能力是多少),使用这些历史数据做一个计算,知道平均每秒能回收多少垃圾,结合预期停顿时间,就能计算出需要回收多少垃圾,就可以对应大概回收哪些 Region。
1.1.4. 一个简单的历史数据的分析算法模型
根据过去10次的GC,造成了多少停顿时间,最终可以计算一个平均每秒能够回收多少垃圾的值。例如,过去10次GC一共收集了10GB内存,一共花费了1s,那么200ms能够回收的垃圾就是2GB,根据这个值(2GB),可以选择一定数量的region分区进行回收。
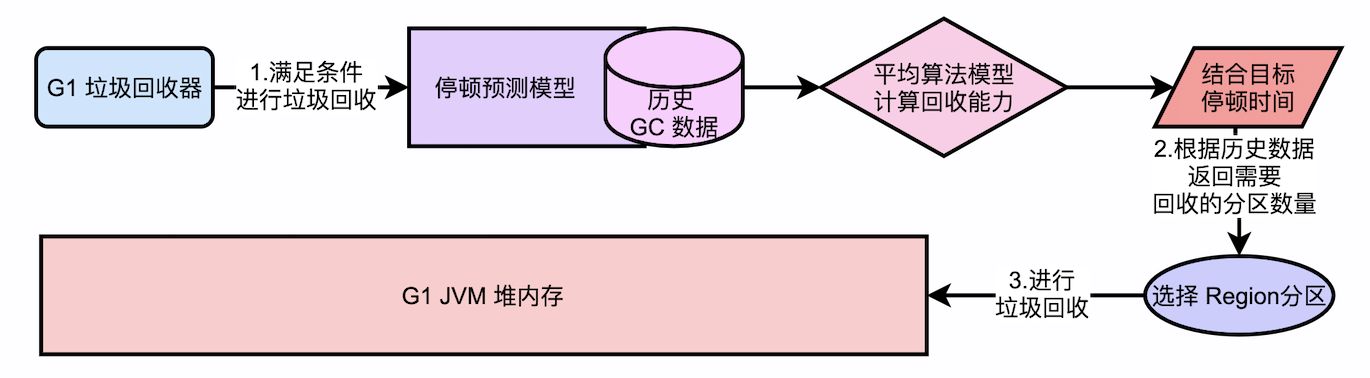
思考:结合内存动态扩展思考,线性算法是否合理?
很显然,内存可能会动态增加减少,新生代、老年代region数量可能也在变化。系统在不断运行,直接用简单粗暴的求平均是不合适的。
1.2. 如何设计一个合理的预测算法?
1.2.1. 一定得是距离本次预测越近的GC,影响比重就占的越高才行
例如,最近有 3次 GC 数据:
- 第1次:权重为0.2:回收垃圾2G:用时200ms
- 第2次:权重为0.3
- 第3次:权重为0.5
1.2.2. G1中的衰减标准差算法预测模型
衰减因子:α;α是一个小于1的固定值,这个值越小,那么最新的数据对结果的影响就越大。
1.2.3. 具体计算模型如下
衰减平均计算公式:
davg(n) = Vn, n=1
davg(n) = (1-α) Vn + α davg(n-1), n>1
例如α=0.6,GC次数为3,三次分别为,第一次回收了2GB,用时200ms,第二次回收了5GB,用时300ms,第三次回收了3GB,用时500ms
计算结果就如下:
davg(1) = 2GB/200ms
davg(2) = (1-0.6) 5GB/300ms + 0.6 2GB/200ms
davg(3) = (1-0.6) 3GB/500ms + 0.6 ( (1-0.6) 5GB/300ms + 0.6 2GB/200ms)
从上述过程中可知,计算出来的平均值davg(3)中,权重最大的就是最后一次GC,在G1中停顿预测模型,就是基于这样的数学模型来实现的。以最合理,最精准的GC预测算法,预测出来本次GC在目标停顿时间范围内能够回收多少垃圾。
1.3. 基于衰减算法模型的垃圾回收过程
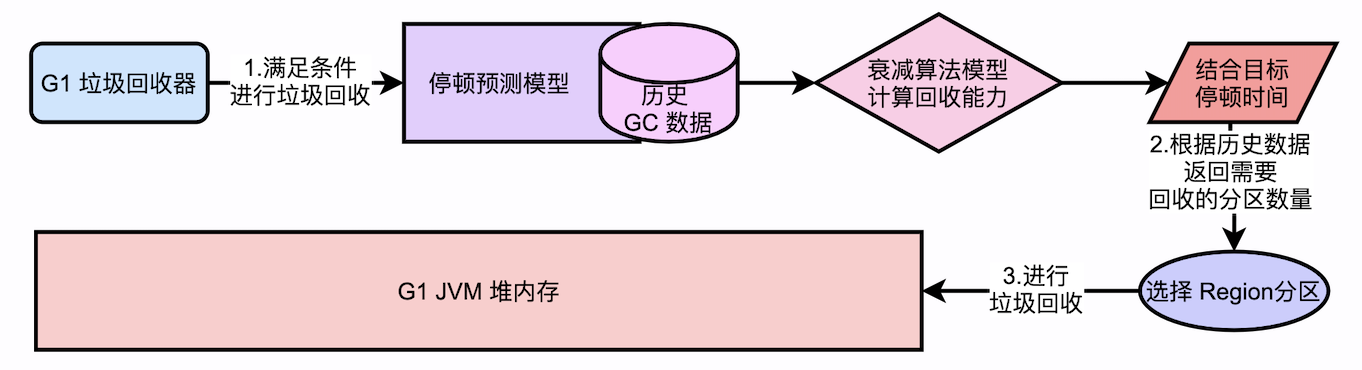
在两种不同的预测模型中,显然,衰减预测模型更能反应出当前JVM的GC运行情况,因此在这种算法模型下,可以更好的帮助G1完成垃圾回收,并且能够更好的满足目标停顿时间。